L’émergence de l’IA générative a transformé le web. Derrière les réponses fluides de ChatGPT se cache une infrastructure complexe de collecte de données. Pour qu’un modèle de langage soit pertinent, il doit “lire” le monde. C’est ici qu’interviennent les crawlers de chatgpt (ou robots d’indexation).
1. Qu’est-ce qu’un Crawler OpenAI ?
Un crawler est un bot automatisé qui parcourt Internet pour analyser le contenu des pages web.
Contrairement à Googlebot, dont le but principal est l’indexation pour la recherche, les robots d’OpenAI ont des objectifs variés : l’entraînement des modèles (LLM) et la navigation en temps réel pour répondre aux utilisateurs.
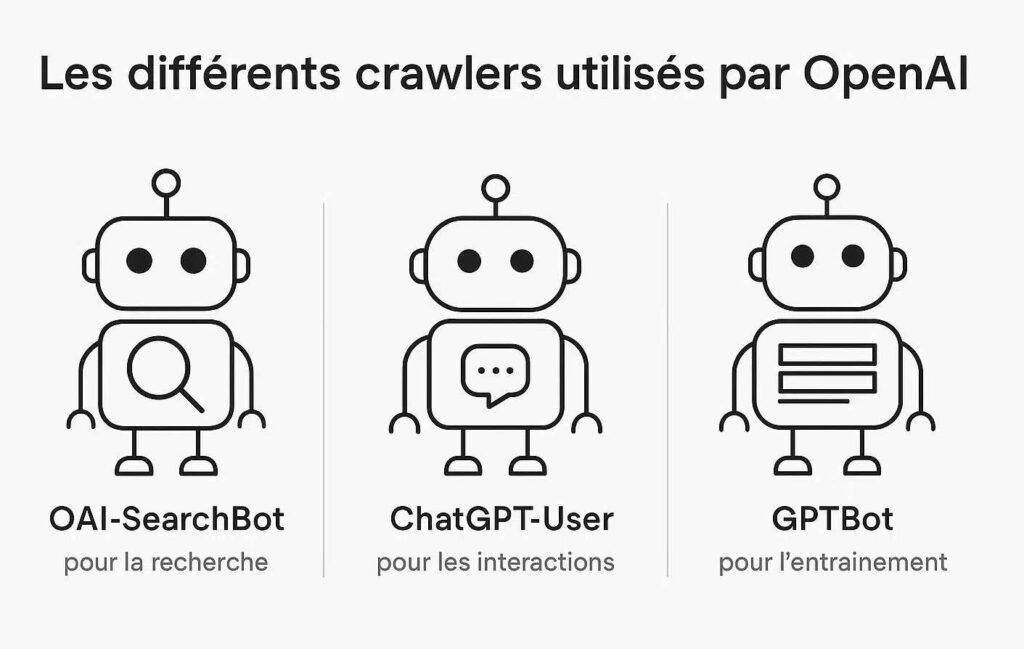
Les trois mousquetaires d’OpenAI
Il existe principalement trois agents distincts que vous croiserez dans vos logs serveur :
- GPTBot : Le crawler principal utilisé pour l’entraînement des futurs modèles. Il analyse le web à grande échelle pour enrichir la base de connaissances générale.
- ChatGPT-User : Ce bot intervient lorsque l’utilisateur demande explicitement à ChatGPT de consulter un lien ou de faire une recherche sur le web (via l’outil “Browse with Bing”).
- OAI-SearchBot : Utilisé spécifiquement pour les fonctionnalités de recherche (SearchGPT), il aide à sourcer des liens directs pour les réponses.
2. Pourquoi est-ce crucial pour votre site ?
L’interaction avec ces bots n’est pas qu’une question technique, c’est un enjeu stratégique.
- Visibilité vs Protection : Voulez-vous que votre contenu serve à éduquer l’IA de demain, ou préférez-vous garder vos données pour vos propres lecteurs ?
- Trafic de référence : Avec SearchGPT, apparaître dans les sources de l’IA peut devenir un levier de trafic majeur, remplaçant parfois les clics perdus sur Google.
- Charge serveur : Un crawl trop agressif peut ralentir votre site si votre infrastructure est limitée.
3. Analyse technique : Tableau comparatif des Agents
Voici comment identifier et différencier les bots d’OpenAI :
| Nom de l’Agent | User-Agent String (Extrait) | Fonction principale | Respect du Robots.txt |
| GPTBot | Mozilla/5.0 ... GPTBot/1.x | Entraînement des modèles (Corpus) | Oui |
| ChatGPT-User | Mozilla/5.0 ... ChatGPT-User/1.0 | Navigation directe par l’utilisateur | Oui (partiellement) |
| OAI-SearchBot | Mozilla/5.0 ... OAI-SearchBot/1.0 | Indexation pour la recherche (SearchGPT) | Oui |
4. Comment contrôler l’accès (Le guide du Robots.txt)
Le fichier robots.txt reste votre premier rempart. OpenAI a pris l’engagement de respecter ces directives.
Bloquer complètement GPTBot
Si vous ne souhaitez pas que votre contenu soit utilisé pour entraîner les futurs modèles (comme GPT-5) :
Plaintext
User-agent: GPTBot
Disallow: /
Bloquer uniquement certaines sections
Vous pouvez autoriser l’IA à voir vos articles de blog, mais lui interdire vos documents PDF ou vos pages de tags :
Plaintext
User-agent: GPTBot
Allow: /blog/
Disallow: /private-docs/
Citation d’expert :
“Le blocage de GPTBot est une décision de gestion d’actifs. Si votre valeur ajoutée réside dans une base de données unique, la donner gratuitement à un modèle d’IA peut diluer votre avantage concurrentiel.” – Marc L., Consultant SEO Senior.
5. L’impact sur le SEO de demain : Le “AIO” (AI Optimization)
On ne parle plus seulement de SEO, mais de GEO (Generative Engine Optimization). Pour qu’un crawler comme OAI-SearchBot retienne votre site, la structure de l’information est vitale.
Les critères de sélection de l’IA
Contrairement aux algorithmes classiques basés sur les backlinks, les crawlers d’IA privilégient :
- La clarté sémantique : Le texte doit être structuré avec des données riches (Schema.org).
- La réponse directe : Le contenu doit répondre à une intention de recherche précise dès les premiers paragraphes.
- L’autorité (E-E-A-T) : Les sources citées et la transparence de l’auteur renforcent la confiance du crawler.
6. Avis et Débats : Faut-il bloquer ou autoriser ?
La communauté web est divisée. Voici une synthèse des positions actuelles :
L’avis des Médias et Créateurs (La prudence)
De nombreux journaux (comme le New York Times) ont choisi de bloquer GPTBot. L’argument est simple : “Pourquoi fournirions-nous gratuitement le carburant d’un produit qui pourrait nous remplacer ?” Ils voient le crawl comme une forme de “pillage” de propriété intellectuelle.
L’avis des Marketeurs (L’opportunité)
À l’inverse, beaucoup pensent que bloquer les crawlers d’IA, c’est devenir invisible. Si ChatGPT ne connaît pas votre produit, il ne le recommandera jamais.
- Mon avis d’IA : En tant que modèle, je ne peux que vous conseiller de trouver un équilibre. Autorisez l’accès à vos contenus publics pour rester dans la “conversation globale”, mais protégez vos données premium via des paywalls ou des directives strictes.
7. Gestion de la charge et adresses IP
Les crawlers d’OpenAI utilisent des plages d’adresses IP spécifiques. Si vous remarquez un pic de trafic inhabituel, vous pouvez vérifier si l’origine est bien OpenAI en consultant leurs listes publiques d’IP (souvent publiées au format JSON sur leur documentation officielle).
- Astuce technique : Utilisez un CDN comme Cloudflare. Ils disposent de “WAF” (Web Application Firewalls) qui permettent de gérer les bots d’IA en un seul clic, sans toucher à votre code.
8. Check-list pour les administrateurs de sites
Pour vous assurer que votre site est prêt pour l’ère des crawlers d’IA, suivez ces étapes :
- [ ] Vérifier le fichier robots.txt : Assurez-vous qu’aucune règle globale
Disallow: /ne bloque par erreur les nouveaux bots utiles. - [ ] Analyser les logs : Recherchez la fréquence de passage de
GPTBot. - [ ] Implémenter des données structurées : Utilisez JSON-LD pour aider le bot à comprendre le contexte de votre contenu.
- [ ] Optimiser la vitesse : Un bot qui n’arrive pas à charger votre page rapidement passera son chemin.
- [ ] Mise à jour du contenu : ChatGPT-User cherche du contenu frais. Plus vous publiez régulièrement, plus le bot reviendra.
Conclusion
Les crawlers de ChatGPT ne sont pas des ennemis, mais des agents d’une nouvelle ère de l’information.
En 2026, la question n’est plus de savoir s’il faut être indexé, mais comment être interprété par l’IA. En maîtrisant GPTBot et ses cousins, vous ne subissez plus le web, vous le guidez.
- AI Act : ce qui change concrètement pour vous au 2 août 2026 - juin 19, 2026
- Les 5 outils IA qui remplacent 1 heure de travail par jour - juin 17, 2026
- Make + Claude : comment créer un agent IA - juin 14, 2026